By Amir Delgoshaie, Senior Director, Data Science, C3 AI, Harsha Vaddi, Data Scientist, C3 AI, Nishanth Mohankumar, Data Scientist, C3 AI, and Akshay Punhani, Manager, Data Science, C3 AI
GPT-5.4 earns near-perfect scores on coding benchmarks. Claude Opus 4.7 follows hundred-step instructions without losing the thread. Gemini 3.1 Pro reasons across million-token contexts. With AI this capable, why would anyone spend the time and money to train their own model?
Because even frontier models hit a wall when the work depends on knowledge they’ve never seen — and when they can push through that wall (via agents, tools, and retrieval), the cost and latency often make it impractical at scale. But advances in open-weight models and parameter-efficient training have changed the calculus: it is now feasible to adapt an open-weight model — one whose parameters are public and modifiable — into a strong specialist on modest hardware. The end result is a model small enough to run fast and cheap in production, trained on the work that actually matters to your business. (For reference, see the OpenHands index on agentic coding costs.)
The catch is that the value of fine-tuning depends on how big the gap is between what a frontier model already knows and what your work actually requires. Most enterprises have proprietary frameworks, internal workflows, codebases, and methodologies that don’t live on the public internet. The question isn’t whether you have that kind of knowledge. It’s whether the gap is large enough that even the strongest frontier model produces output that looks right but doesn’t work.
We’ve seen this firsthand in code generation. Our proprietary C3 AI Type System — a domain-specific language for defining data models, analytics, and business logic — sits well outside any pretraining set, so we built a specialist model called Narwhal to work with it. The same dynamic shows up anywhere proprietary work outpaces what frontier models have been exposed to: drug discovery pipelines, financial modeling systems, industrial control languages, legal contract analysis. What follows is the case we’d make to anyone in those domains, drawn from what we learned building Narwhal.
Why Fine-Tuning a Domain-Specific LLM Is Newly Practical
1. Open-weight models are now frontier-class
The numbers tell the story. As of this writing, Alibaba’s Qwen 3.6 27B matches Anthropic’s Sonnet 4.6 on SWE-bench (a widely used software engineering benchmark) and scores 95% on instruction-following benchmarks. NVIDIA’s Nemotron 3 Nano (30B total, just 3B active per token) hits 99.2% on AIME math reasoning and handles million-token contexts with 3x the throughput of comparable models. Both are open-weight and free to fine-tune.
And these aren’t stripped-down versions of bigger models. Rather, they’re purpose-built to be small, fast, and strong, and they keep getting better with each release cycle.
2. Better Base Models Yield Better Domain Specialists
This is the less obvious shift, but the most powerful one. When the base model gets better at general tasks, even a simple step like continued pre-training on your own unstructured data yields proportionally better results on your specific tasks. The gains compound with every generation, so every new release of open-weight models lifts your domain model along with it.
3. Reinforcement Learning Now Works on Modest Hardware
For any task where the model’s output can be objectively scored, you can now use reinforcement learning (RL) to directly optimize for that outcome. Define a reward function around what correct means in your domain, and let RL sharpen the model precisely where it matters most.
Techniques like GRPO (Group Relative Policy Optimization) eliminate the need for a separate reward model, which was the expensive bottleneck in older RL approaches. Instead, GRPO scores multiple outputs relative to each other within a group, so you can run RL on the same setup you’d use for supervised fine-tuning.
How We Built Narwhal: A Domain-Specific Coding Model
Here’s how those three shifts played out building Narwhal. The C3 Agentic AI Platform runs on the C3 AI Type System and a set of closed-source Python and JavaScript SDKs (software development kits) used to build C3 AI applications. Before we committed to fine-tuning, we wanted to make sure we couldn’t get there with prompting alone.
The first thing we tried was the lowest-effort path: keep the frontier model, give it everything it needs at inference time. Detailed prompting, retrieval against our docs, agentic setups with tool access. If any of that worked well enough, we wouldn’t have needed to fine-tune anything.
We evaluated frontier models (GPT-5.4 and Claude Opus 4.6) on C3 Code Eval, our internal coding benchmark of 97 real-world tasks. Each task presents an empty function with a docstring, and the model must complete the implementation. We then run unit tests on the generated code. We tested two approaches: retrieval-augmented generation (RAG), using one-shot documentation search, and agentic setups where frontier models had access to skills and tools for interacting with our platform.
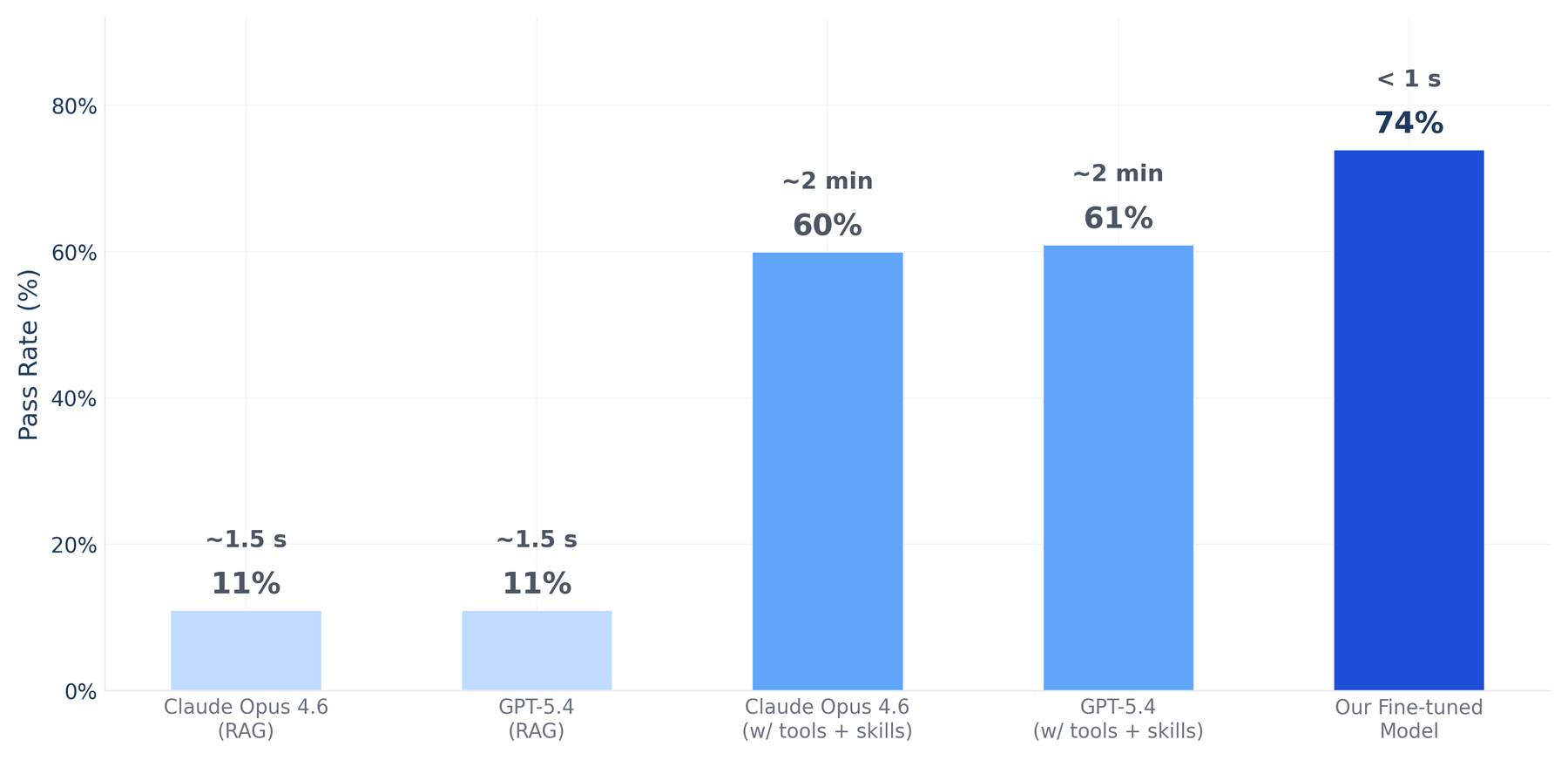
Figure 1: C3 Code Eval pass rate and response time. Agents with access to domain specific tools and skills reach ~60% but take ~2 minutes per query. RAG is faster but often produces inaccurate results. Our internal finetuned LLM delivers the highest pass rate in under a second.
The results tell a clear story:
- RAG: 11% (~1–2 s response time). Using one-shot search against our documentation, frontier models retrieved relevant context but showed no measurable improvement. Access to information turned out to be only part of the problem; the models lacked the deep fluency to use what they retrieved. RAG is fast, but speed doesn’t help if the output is wrong.
- Agents with tool access: 60–61% (~2 min response time). We gave frontier models access to skills and tools that provide context about our platform APIs, infrastructure, and documentation. GPT-5.4-medium and Claude Opus 4.6 both reached ~60%, a big jump over RAG, but at ~2 minutes per query, impractical for real-time use cases.
- Narwhal V11 (27B, fine-tuned): 74% (<1 s response time). Our domain-specific model outperforms every frontier configuration, at roughly 1/20th the parameter count of GPT-5.4, running on a single GPU with sub-second latency. It’s both the most accurate and the fastest option.
Our takeaway, which we expect generalizes beyond code: for domains that are large, complex, and deeply specialized, prompting and retrieval cap out well below what production needs. Fine-tuning got us past that cap, fast enough to deploy.
Continued Pre-Training Lifts Every Base-Model Upgrade
Narwhal’s recipe is straightforward: take a strong open-weight base model, run continued pre-training on our proprietary codebases (so it absorbs domain patterns), then apply reinforcement learning (so it gets measurably better at specific tasks). Across five generations, we’ve found that a considerable portion of the gains come from the continued pre-training stage alone — just swapping in a stronger base model gives us a significant lift in domain performance without changing anything else in the recipe.
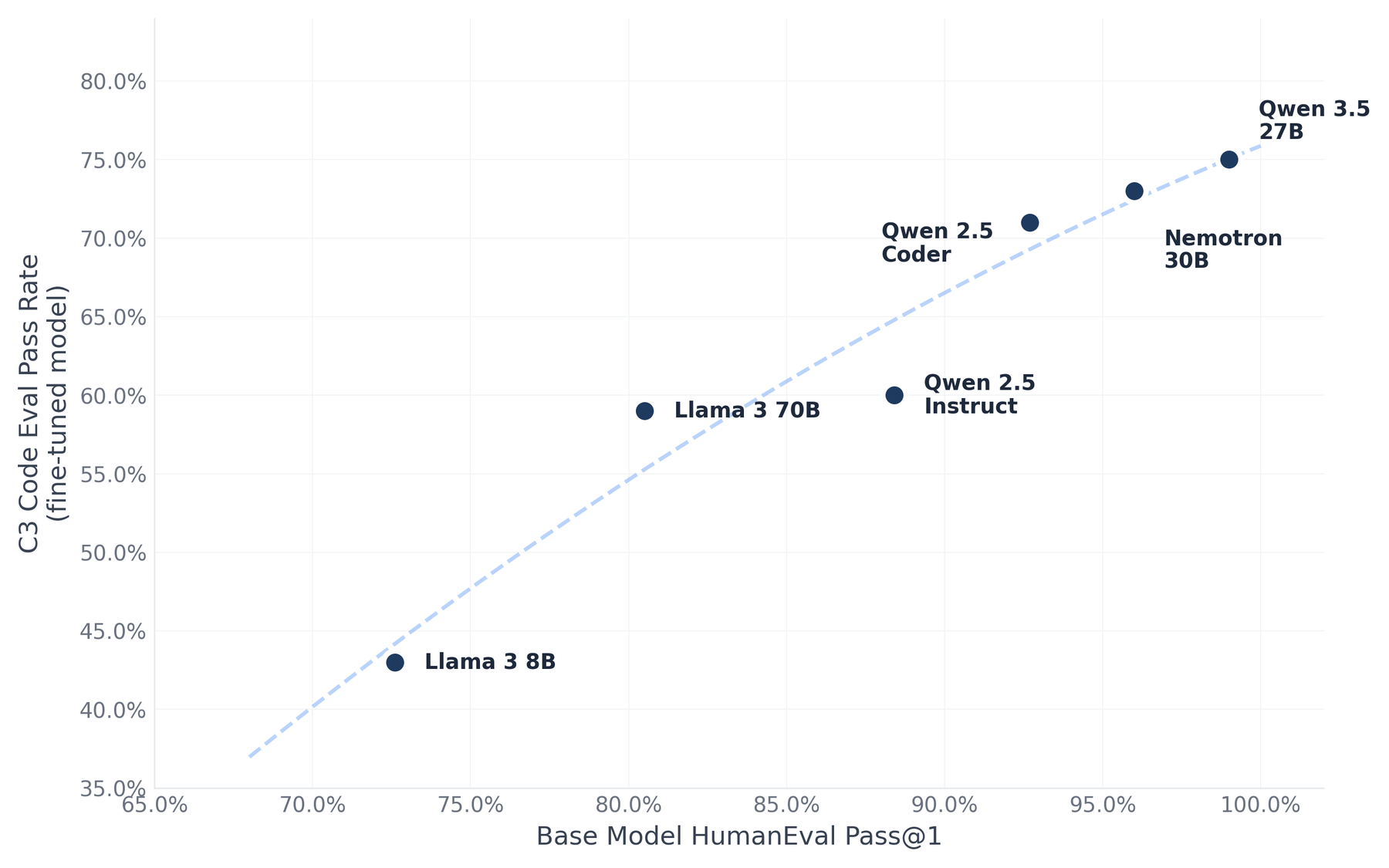
Figure 2: Each dot represents a generation of our model after continued pre-training on domain data. The x-axis is the base model’s score on a general benchmark; the y-axis is its domain performance after learning from our proprietary codebases. Better base models consistently yield better domain specialists.
The pattern is consistent: every time we swap in a stronger base, domain-specific performance improves in lockstep, without changing anything else in the rest of the recipe. You automatically benefit from every new generation of open-weight models.
But notice the persistent gap in Figure 2: even at ~99% general capability, the domain score is 75%. Continued pre-training transfers a lot of capability from the base model, but it doesn’t close the distance entirely. In our case, this 25-point gap held steady even as base models got stronger. Closing it required a different technique.
Reinforcement Learning Closes the Gap That Pre-Training Can’t
From real-world usage of Narwhal, we identified a set of questions where the model consistently produced poor answers and struggled with code in that area. We collected those questions into a training dataset and defined a structured rubric covering correct structure, proper use of platform syntax, and correct SDK methods and parameters. We then used an LLM as a judge to score each candidate answer against that rubric, producing a scalar reward for GRPO to train on. This gave us a consistent enough signal to learn from without requiring hand-labeled examples for every question. During RL training, the model generates multiple candidate answers for each question, scores them against the rubric via the judge, and updates itself to favor the higher-scoring outputs.
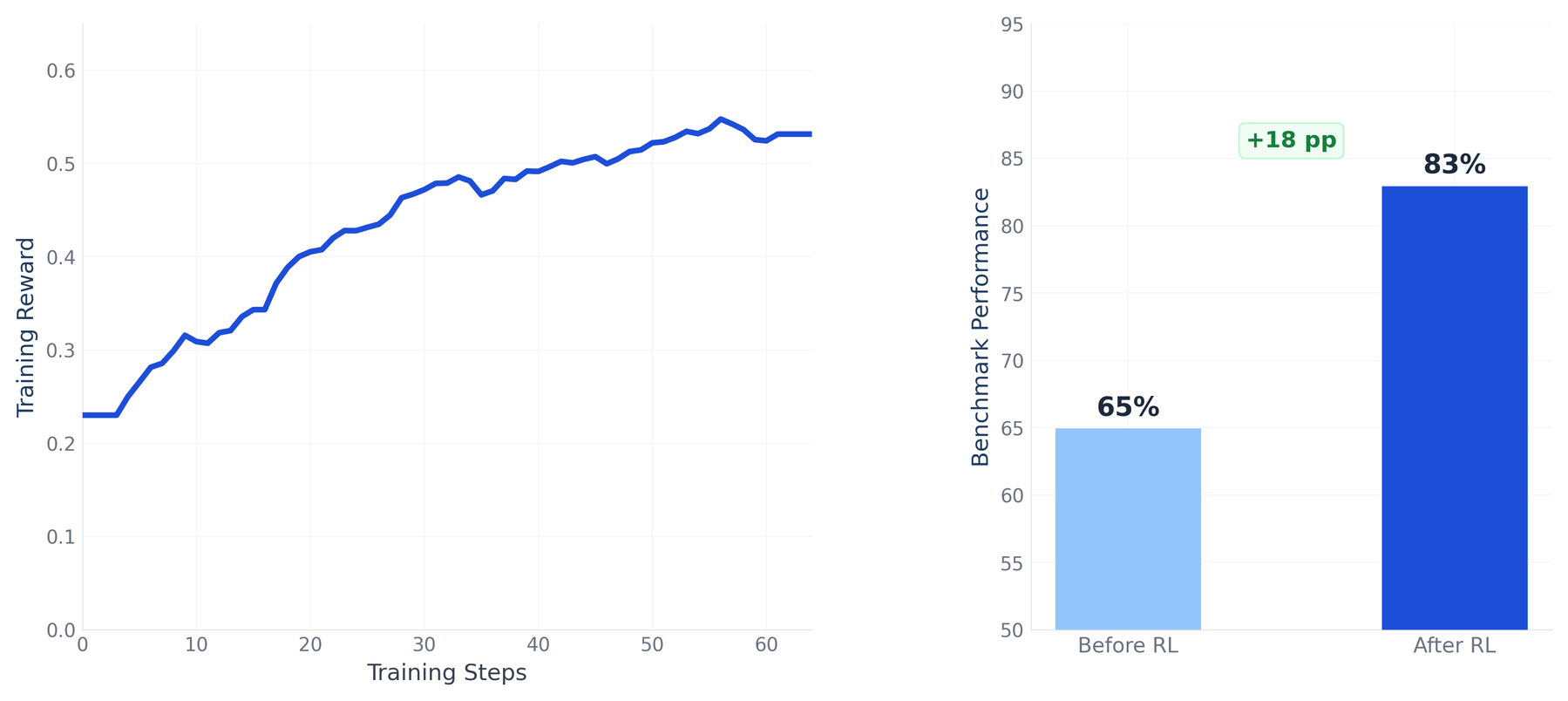
Figure 3: (Left) Training reward increases steadily over GRPO steps, (Right) Performance on a held-out QA evaluation improves from 65% to 83%, showing that RL gains generalize beyond the training distribution.
Performance on held-out Q&A questions improved by 18 percentage points, and the gains were not limited to that category. Performance on C3 Code Eval, our function-completion benchmark, also improved by 6–8 points, even though RL training targeted only Q&A-style questions, not code completion tasks. That cross-task transfer suggests the model is learning structural patterns in our platform’s APIs and syntax rather than memorizing answers to the specific questions it trained on.
We apply similar RL techniques to other task categories, including code completion and documentation Q&A, each with its own definition of correct. In our experience, the limiting factor isn’t the algorithm. It’s how cleanly you can define what correct means for the task at hand. The combination of continued pre-training and targeted RL has produced a model that is both fast and strong across our different use cases.
Five Lessons From Five Generations of Narwhal
A few patterns have held up consistently across every generation:
- Frontier prompting and retrieval cap out below production needs. On our benchmark, the best frontier configuration we tested topped out around 60% pass rate at ~2 minutes per query. Useful, but not a silver bullet for every use case.
- Better base models give you a better specialist for free. Across five base-model swaps, domain performance improved every time we picked a stronger open-weight base, with no other change to our pre-training recipe.
- Continued pre-training alone leaves a stubborn gap. Even with very strong base models, our domain score plateaued around 75%. Closing the rest required something more targeted than more pre-training data.
- RL generalizes beyond the training task. The +18 point gain on Q&A came with a 6–8 point lift on C3 Code Eval, our function-completion benchmark. Even though RL targeted the Q&A task, the training algorithm generalized improvements to other related tasks.
- Defining correct was the hardest part of our RL work. Algorithm choice mattered less than rubric design. Because our reward function is an LLM judge, rubric clarity directly determined reward consistency. The cleanest rubrics produced the largest gains; vaguer criteria introduced scoring noise that RL could not learn through.
One Specialist Model, Many Production Surfaces
One thing we didn’t expect: the model we built for a single use case ended up running almost everywhere our domain knowledge matters. Think of it less as a feature and more as a foundation — the same training investment applies across every surface where users touch the platform, with each new deployment costing almost nothing additional. The same Narwhal model now serves:
- IDE integration: helping developers write domain-specific code (agentic coding through C3 Code)
- AI agent tools: providing tool definitions for AI agents interacting with the platform (mcp.c3.ai)
- Customer support: answering troubleshooting questions on our community platform (community.c3.ai)
- Documentation Q&A: powering search and answers across technical docs (docs.c3.ai)
One training investment, four production surfaces, and each new one building on top of the existing foundation model.
This approach can also pay off across customer domains. A manufacturer can fine-tune on decades of equipment manuals and repair histories, and technicians can diagnose machine faults their first day on the floor. A financial services firm can adapt a model to its own product documentation and compliance policies before letting it touch a customer service workflow. A national grid operator can tune a model on its transmission topology and operational data to monitor faults across the network.
Want to see what domain-specific AI can do for your enterprise?
Join the C3 Generative AI Accelerator. Live workshops where you’ll build production-ready AI applications using our agentic development stack. Or contact us to discuss how domain-specific AI can accelerate your teams.
Amir Delgoshaie is a Senior Director of Data Science at C3 AI, where he leads generative AI foundations for developer productivity, including domain-specific LLMs, MCP infrastructure, and coding agents used to build enterprise applications. He previously worked on core components of the C3 Agentic AI Platform and led the development and deployment of large-scale AI applications across energy, utilities, manufacturing, and supply chain.
Harsha Vaddi is a Data Scientist at C3 AI, focused on Applied AI and LLM research. He develops scalable AI capabilities across developer-facing platforms, improving model quality and user experience through advancements in retrieval, evaluation workflows, and intelligent assistant systems. His work spans data engineering, model development, and automated evaluation, and he works extensively with reinforcement learning and large-scale LLM techniques to solve real-world enterprise problems. Harsha holds a Master of Science from the Georgia Institute of Technology and a bachelor’s degree from the Indian Institute of Technology Hyderabad
Nishanth Mohankumar is a Data Scientist at C3 AI, where he builds generative AI capabilities that enhance the C3 AI development experience. Among other things, his work centers on iterative improvement driven by user feedback, developing large-scale synthetic data generation pipelines for LLM training and evaluation, etc. Nishanth holds a master’s degree from Carnegie Mellon University and a bachelor’s degree from National Institute of Technology, Karnataka.
Akshay Punhani is a Data Science Manager at C3 AI, where he focuses on enhancing developer productivity across the C3 Agentic AI Platform by building tools that streamline development, testing, and deployment for engineering and data science teams. He has also contributed to major initiatives in Sustainability, Asset Performance, and Generative AI, supporting both customer engagements and product development. Akshay holds a master’s in data science from the University of California, Berkeley.
The domain-specific model described in this post, Narwhal, is developed by C3 AI’s Developer Productivity DS Pod.
Share your thoughts and tag us on LinkedIn and X.