Artificial intelligence and machine learning (AI/ML) is changing the game for every company and analytics professional. Predictive algorithms are anticipated to help you (and your competitors) better serve customers, manage supply chains, release new products, and manage risk to the tune of $16 trillion in net new economic value over the next several years. But these algorithms aren’t going to do it themselves.
AI/ML algorithms learn from historical data to generate predictions, which makes them both powerful and prone to various pitfalls. Feed algorithms the wrong data, evaluate them by the wrong metrics, or misinterpret the results, and you’ll end up with models that don’t represent the real world and lead you and your business down the wrong path.
This blog series — AI Traps and How to Avoid Them — is intended help you capitalize on the value that AI can deliver while avoiding common pitfalls. In this first installment, we’re laying out what good data means when training an AI algorithm and how to go about getting it.
Using Good Data
AI algorithms — that do everything from making predictions and recommendations to identifying clusters and detecting objects — learn from historical examples so having good data is essential for training good models. But good doesn’t just mean a lot. Real-world data almost always has to be curated to get good results—let’s talk about the most common methods to getting there.
Imbalanced Classes
Algorithms affected: Classification algorithms
Imbalance refers to target variables (also known as classes) within a dataset appearing with different frequency. A list of transactions being used to train a fraud prediction model, for instance, might contain 999 instances of legitimate transactions for every one that’s fraud. As the name suggests, imbalanced classes are unique to classification problems; they can happen in both a binary class or a multiclass. The latter meaning all samples belong to one of two groups and the former meaning samples belong to one of three or more groups.
Imbalanced classes can cause problems because AI/ML algorithms are greedy—models trained on imbalanced classes are likely to overpredict for higher-frequency classes. In our fraud prediction example, this would mean it would predict more legitimate transactions.
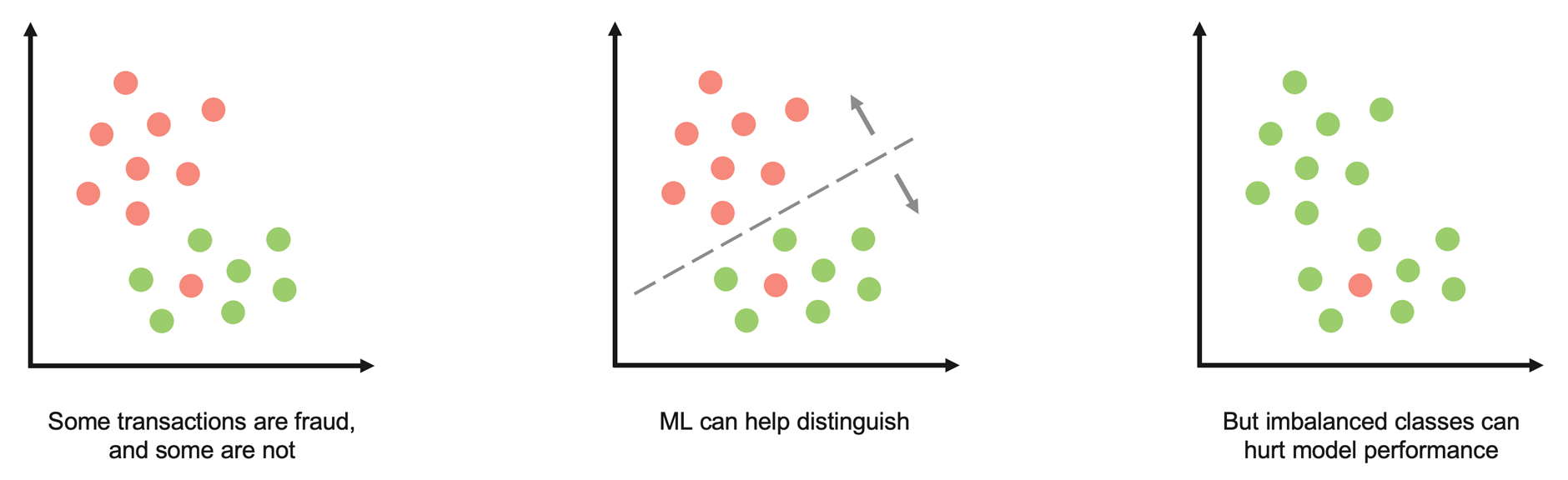
Imbalanced classes are common in real-world ML use cases. Some examples include churn prediction, conversion prediction, and credit default prediction.
Imbalanced classes can yield bad classifiers
How to Get Balance
Start by looking at the right model metrics; here’s a good model metrics guide if you want to brush up on the fundamentals. Accuracy, for example, might look good even if the model is useless. Our fraud prediction model could score every transaction as legitimate and get 99.9% accuracy but be useless for catching fraud. Instead, look at precision and recall to determine how good your model is at predicting the results you’re interested in.
Evaluating the right performance metrics will ensure you don’t use a bad model. But there are also methods to help you train a good model even if the classes are imbalanced. The most common methods involve resampling the dataset—manipulating the data you train on so that classes are more balanced when training begins.
Resampling comes in two forms. Undersampling keeps all the instances of the rare class and selects an equal number of instances randomly from the abundant class. Oversampling artificially increases the instances of the rare class, either by duplicating them or by artificially creating new ones. If you’re interested in learning more about this technique, read up on SMOTE.
No-code analytics solutions like C3 AI Ex Machina make it easy to profile, resample, and balance large, diverse datasets. C3 AI Ex Machina lets you oversample or undersample your data to deal with imbalanced classes. You can select the approach or you can let C3 AI Ex Machina automatically decide for you.
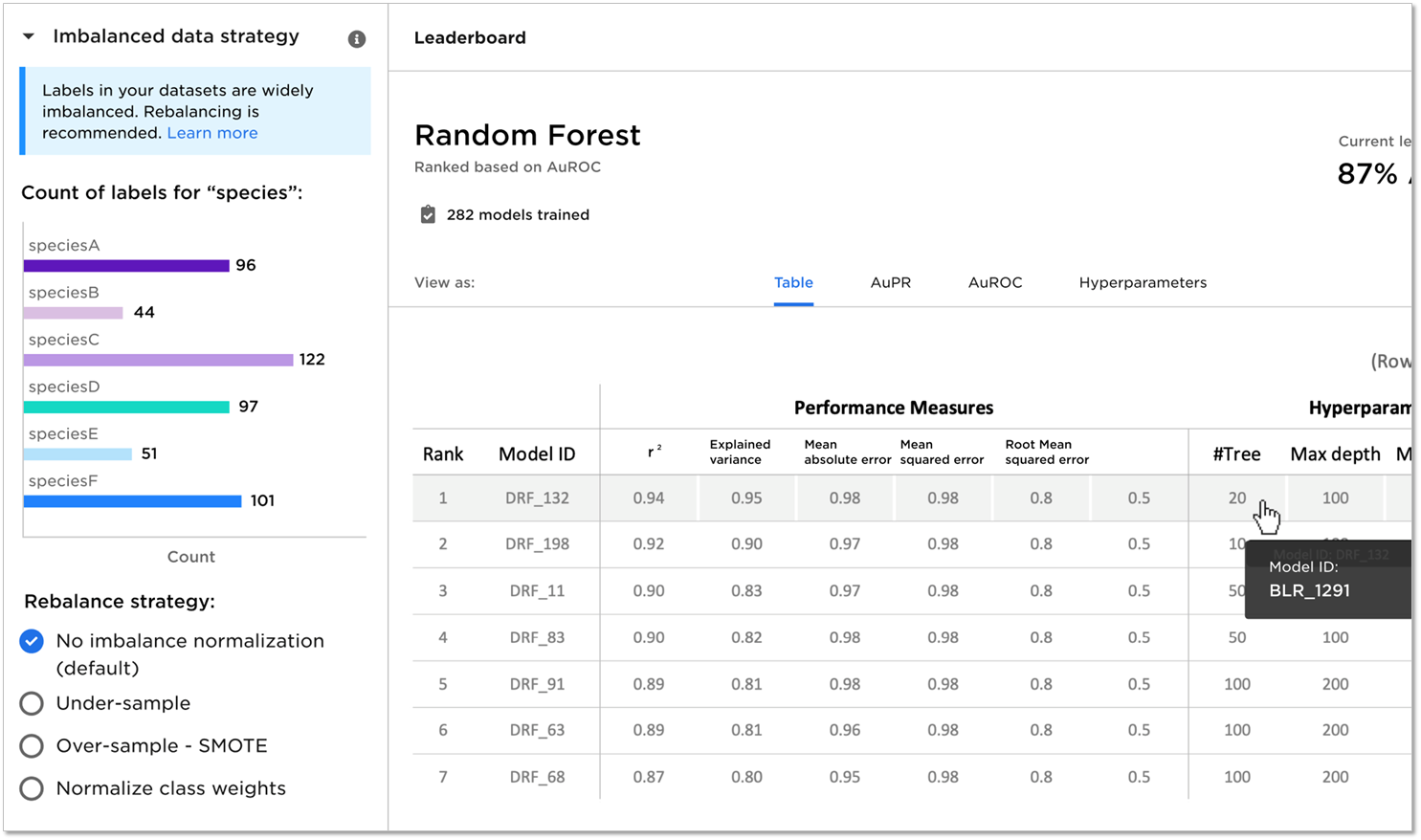
Undersample or oversample before training your classifier or let C3 AI Ex Machina do it for you
There isn’t a hard-and-fast rule on when to use oversampling vs. undersampling. Undersampling is more appropriate when you have datasets that are large enough that you can afford to drop values. When in doubt, try both, and then select the model that performs better.
In the next blog, we’ll explore how to address the challenges associated with datasets containing features that differ greatly in range or magnitude from each other.