Welcome to our second blog in the series, AI Traps and How to Avoid Them. Our previous post focused on the importance of using good, balanced data for model training. In this post, we’ll explore how to address the challenges associated with training machine-learning models using datasets containing features that differ greatly in range or magnitude. Features within datasets are simply a measurable quantity that is being tracked for analysis — for example, the balance of a bank account or the number of transactions within that account, all data that are needed to develop an accurate fraud detection model.
Understanding Dataset Features with Different Scales
Types of algorithms affected: linear regression, logistic regression, K nearest neighbors, neural networks
Having data with feature sets (or columns) that differ greatly in range and magnitude from each other isn’t uncommon. Continuing with the example of data for a fraud model, client balances, accounts, and transaction counts all have different units, magnitudes, and ranges, and they might all be relevant.
And although you know that balance isn’t one million times more important than the number of accounts, your model doesn’t.
| Client | Balance | # Accounts | # Transactions |
|---|---|---|---|
| Client A | $1,598,201 | 5 | 47 |
| Client B | $489,203 | 3 | 140 |
| Client C | $7,620,939 | 4 | 2,915 |
| Client D | $224,899 | 2 | 921 |
| Client E | $2,301,292 | 3 | 84 |
We’ll avoid getting bogged down in the math here, but there are a few issues you might run into if you don’t scale your features ahead of model training.
First, the way a classifier will work to understand the relational relevance of feature sets is by calculating the distance between observations and assigning them to classes accordingly. If the ranges of input features differ greatly, these distance calculations will be affected, and your model won’t produce reliable results — for fraud detection, this might produce too many false positive alerts.
Feature scaling entails putting your feature values into the same range and is important in the development of regression algorithms for a couple reasons. First, without it, you risk introducing collinearity, which is a linear relationship between features that negatively affects the statistical power of your model. Second, if you use regularization instead of scaling to prevent overfit, you will unfairly penalize features with small ranges.
Another benefit is that if features are scaled, algorithms that use gradient descent to optimize will train faster. This affects popular machine learning algorithms such as linear and logistic regression, KNN, and artificial neural networks. But tree-based algorithms like random forest and gradient boosted trees won’t be affected.
How to Address
There are some established techniques that can help us solve this scaling issue and move features with high variance onto similar scales before training begins. Min-max normalization and standardization are two of the most popular:
- Min-max normalization scales values so that they fall between 0 and 1.
- Standardization scales all values around a mean of 0 and a standard deviation of 1.
There are a couple ways to determine which technique to choose. In general, standardization is more common and is generally more effective if your values have a normal distribution (i.e., look like a bell curve). Min-max normalization is more effective when your data are not normally distributed. Start by profiling your raw data — and if you still aren’t sure, try both and see which gives you a better model.
| Client | Balance | # Accounts | # Transactions |
|---|---|---|---|
| Client A | -0.2818002 | -0.6322506 | 1.4032928 |
| Client B | -0.6500266 | -0.5563218 | -0.3508232 |
| Client C | 1.7179610 | 1.7092974 | 0.5262348 |
| Client D | -0.7377849 | 0.0813174 | -1.2278812 |
| Client E | -0.0483492 | -0.6020424 | -0.3508232 |
Model data after standardizing — all columns are centered at 0 with standard deviation 1.
How to Accelerate Feature Scaling
Data normalization and standardization are available out of the box with our low-code, no-code application, C3 AI Ex Machina and will help you deal with features that demonstrate high variance. You can pick the strategy yourself or you can let C3 AI Ex Machina decide the best path forward.
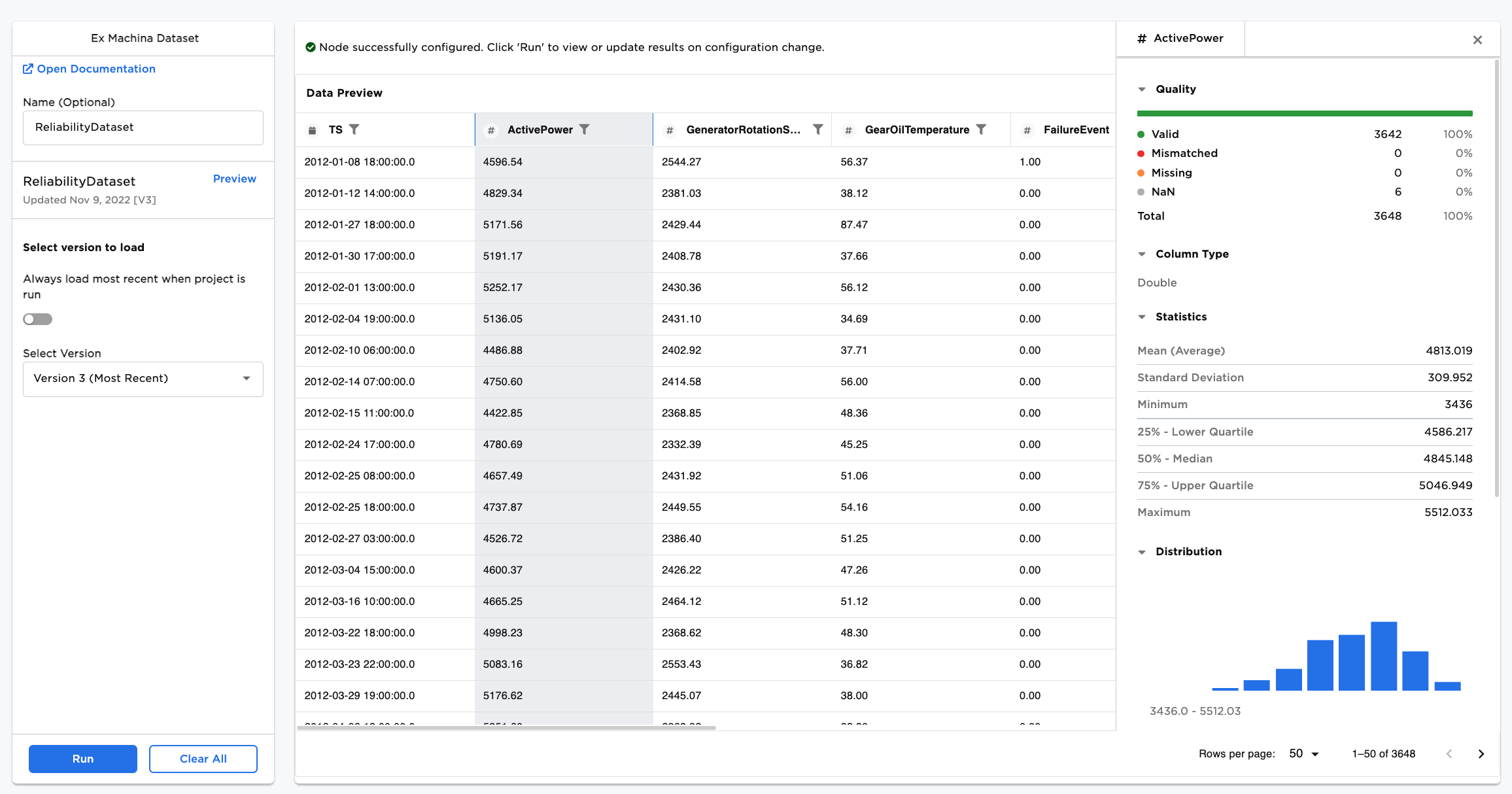
Standardize and normalize your all your features with just a few clicks in C3 AI Ex Machina.
Successfully identifying and addressing imbalanced classes and features with different scales are both critical to fueling your AI/ML efforts with good quality data. With the basics of good data established, we’ll use our next blog post to dive into AI/ML model training how to deal with underfit and overfit.