

Glossary
What is Information Leakage?
Information (or data) leakage is undesired behavior in machine learning during which information that should not be in the training data inflates the model’s ability to learn, causing poor performance at prediction time or in production. Models subject to information leakage do not generalize well to unseen data.
There are multiple types of data leakage, including:
- Explicit leakage, in which some features represent transformation of or a proxy for the target variable. This can happen during the pre-processing or feature engineering phase when some transformations are blindly applied to both training and testing data.
- Independent and identically distributed, or i.i.d., samples. i.i.d (). For time-series problems, this can happen when data is randomly split and some training examples occur after the testing observations, also known as implicit leakage. Under these conditions, data available to a model could potentially include some future information that the model would not have access to in a real-world scenario.
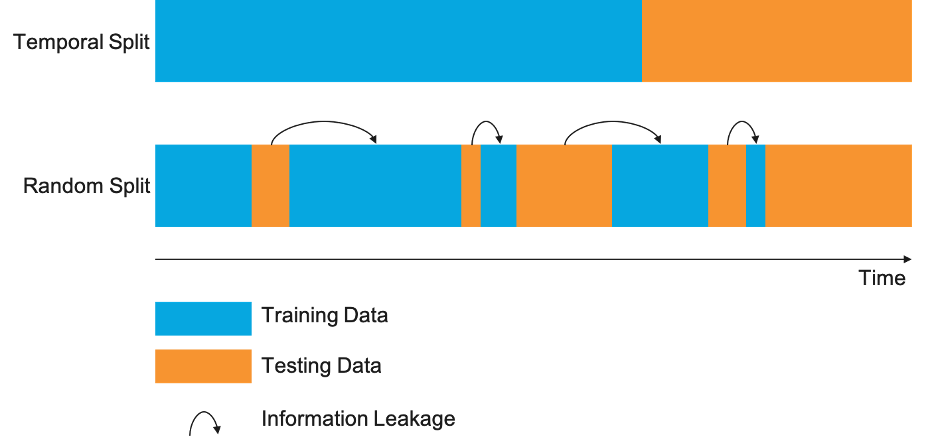
Why is Information Leakage Important?
Avoiding or detecting information leakage early is important to prevent models from learning the wrong signals and overestimating their value before they go into production.
In addition to following data science best practices, model interpretability is a great tool to identify and fight information leakage.
How C3 AI Helps Organizations Detect and Avoid Information Leakage
At C3 AI, data scientists are well-versed in information leakage problems and how to detect them. C3 AI carefully splits the data into separate groups – training, validation, and test sets – and keeps the test set intact to report the final performance after the model has been optimized on the validation set. For time-series data, C3 AI applications always apply a cut-off timestamp or time-series cross-validation.

- C3 AI applications meticulously track the data lineage from raw data all the way to engineered variables to ensure no detrimental information is leaking. In the C3 AI Reliability application, for example, all the features used to predict a failure are derived from data observed and logged before the failure event log time.

- The C3 AI Platform leverages several interpretability frameworks, such as SHAP (SHapley Additive exPlanation) and ELI5 (Explain Like I’m 5), during development of AI systems to detect information leakage by examining feature contributions.


