Glossary
Data Cleansing
What is Data Cleansing?
Data cleansing is the process of improving the quality of data by fixing errors and omissions based on certain standard practices. These improvements include removing duplicate entries, filling in missing values, converting data to the right type, format, or set of standard values, and aggregating or normalizing values. One example is standardizing address information per the postal system database, adding a postal code if needed, parsing street numbers from street names, and standardizing on state and country abbreviations. Time series may be filled in with interpolated values or aggregated by average, minimum, or maximum functions over a time interval (minute data converted to hourly values, for example). The goals of data cleansing are validity, accuracy, consistency, uniformity, and completeness.
Why is Data Cleansing Important?
In order for data science to be able to accurately derive insights from data, that data needs to accurately and consistently represent its subject matter for comparisons and analysis in a way that the machine learning models can interpret. Everyone living in California should have the same value in the state field and have the same birth date format to calculate age properly. A “yes” in the database may need to be coded as a Boolean “1” as input to a binary classifier model. The data cleansing process takes care of these issues, so that the data is ready for analysis. It is critical for the data scientist to understand the data cleansing process to know how the data may have been transformed from its raw form.
Data Cleansing in the C3 AI Platform
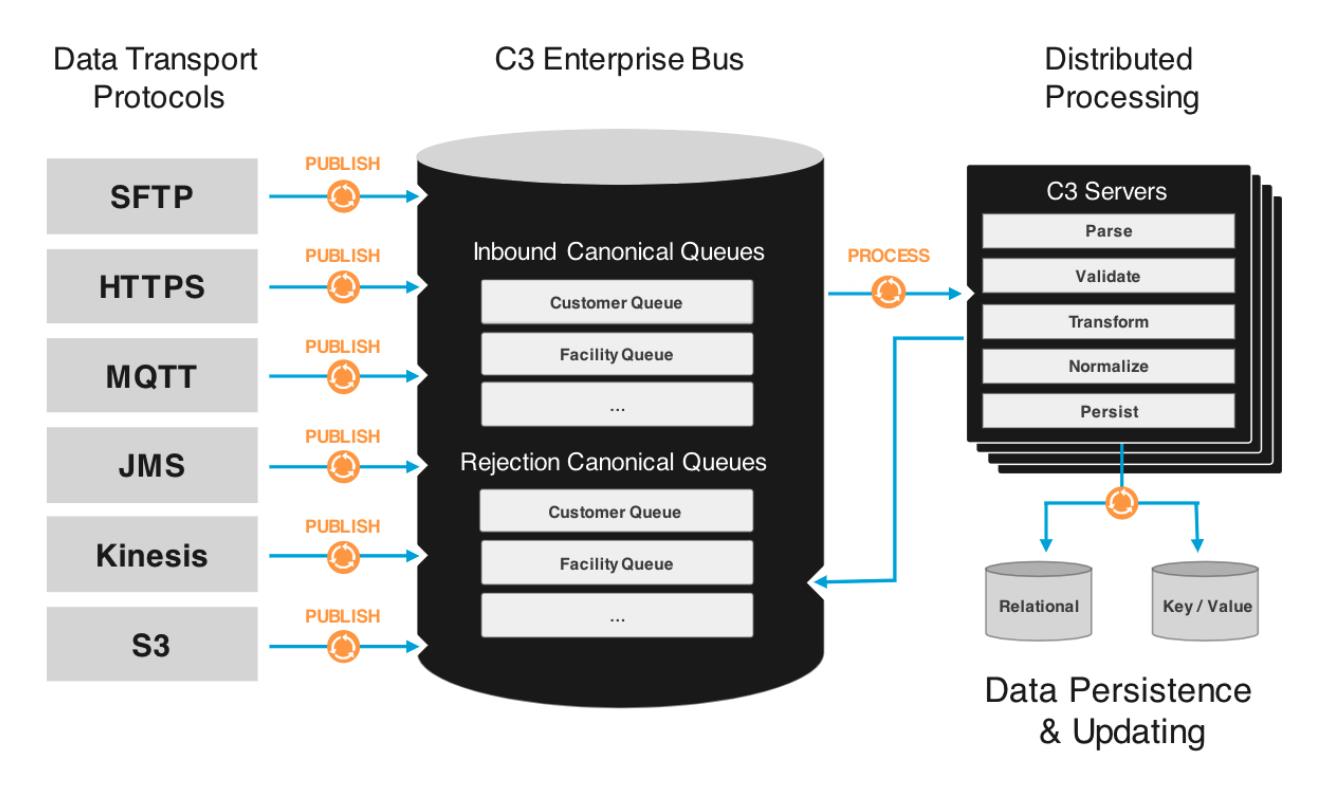
As a component of the C3 AI® Platform‘s integration services, the C3 AI Data Integrator enables the ingestion and data cleansing of inbound data. Within the C3 AI Data Integrator, the C3 AI Enterprise Bus manages canonical queues. Canonicals are modeled interfaces for different inbound data based on canonical schemas. Canonical transforms determine how the source data is converted to the canonical format used as input for further analysis.
Data are delivered to the enterprise bus via files placed in the file system (for example, S3), SFTP, API, and messages (for example, JMS or Kinesis). Distributed processing then loads each delivered record in parallel across worker compute nodes that perform parsing, validation, data cleansing, transformation, post-processing, and persistence as appropriate.