

Glossary
What is Local Interpretable Model-Agnostic Explanations (LIME)?
LIME, the acronym for local interpretable model-agnostic explanations, is a technique that approximates any black box machine learning model with a local, interpretable model to explain each individual prediction.
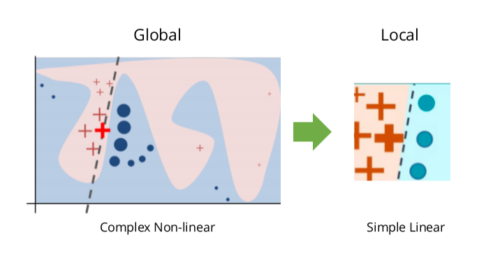
The idea stems from a 2016 paper1 in which the authors perturb the original data points, feed them into the black box model, and then observe the corresponding outputs. The method then weighs those new data points as a function of their proximity to the original point. Ultimately, it fits a surrogate model such as linear regression on the dataset with variations using those sample weights. Each original data point can then be explained with the newly trained explanation model.
More precisely, the explanation for a data point x is the model g that minimizes the locality-aware loss L(f,g,Πx) measuring how unfaithful g approximates the model to be explained f in its vicinity Πx while keeping the model complexity denoted low.
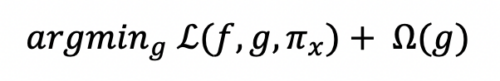
Therefore, LIME experiences a tradeoff between model fidelity and complexity.
Why is LIME Important?
For humans to trust AI systems, it is essential for models to be explainable to users. AI interpretability reveals what is happening within these systems and helps identify potential issues such as information leakage, model bias, robustness, and causality. LIME offers a generic framework to uncover black boxes and provides the “why” behind AI-generated predictions or recommendations.
How C3 AI Helps Organizations Compute LIME
The C3 AI Platform leverages LIME in two interpretability frameworks integrated in ML Studio: ELI5 (Explain Like I’m 5) and SHAP (Shapley Additive exPlanations). Both techniques can be configured on ML Pipelines, C3 AI’s low-code, lightweight interface for configuring multi-step machine learning models. Data scientists use these techniques during the development stage to ensure models are fair, unbiased, and robust; C3 AI’s customers use them during the production stage to spell out additional insights and facilitate user adoption.
1Marco Tulio Ribeiro, Sameer Singh, Carlos Guestrin, “Why Should I Trust You?: Explaining the Predictions of Any Classifier”



