

Glossary
Shapley Values
What are Shapley Values?
Shapley values can be used to explain the output of a machine learning model. The Shapley value is a concept in game theory used to determine contribution of each player in a coalition or a cooperative game. Assume teamwork is needed to finish a project. The team, T, has p members. Knowing that the contribution of team members during the work was not the same, how can we distribute the total value achieved through this teamwork, v=v(T), among team members? Shapley value, φm (v), is the fair share or payout to be given to each team member m. The φm (v) is defined as
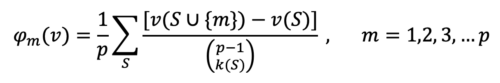
For a given member, m, the summation is over all the subsets S, of the team, T={1,2,3,…,p},that one can construct after excluding m. In the above formula, k(S) is the size of S, v(S) is the value achieved by subteam S, and v(S∪{m}) is the realized value after m joins S.
We define a fair allocation to be an allocation that satisfies:
1. Efficiency: The total of individual contributions is equal to the team’s realized value:
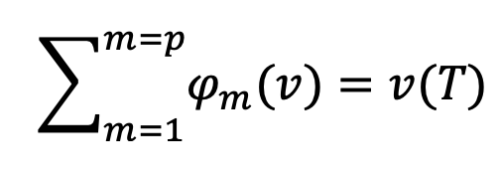
2. Symmetry: Two team members with the same added value have the same share:
if v(S∪{m})=v(S∪{n}), then φm (v) = φn (v)
3. Linearity: If the team participates in several projects (say two projects), each yielding v(T),u(T), then adding the share of each member in the different projects is the same as finding his/her share using the total gain v(T)+u(T). In other words, the shares are additive:
φm (v + u) = φm (v) + φm (u)
And, φm (av) = a φm (v).
Shapley values have found applications in several fields. They can be applied in machine learning to explain feature contributions where features are the players or team members and the model prediction is the payout of the game or teamwork.
To calculate the importance of feature j, we can intuitively think of the process as, for each iteration, drawing feature values in random order for all features except for feature j before we then calculate the difference of prediction with and without feature j. The Shapley value is computed by taking the average of difference from all combinations. Essentially, the Shapley value is the average marginal contribution of a feature considering all possible combinations.
The main advantage of Shapley value is that it provides a fair contribution of features with mathematically proven theory and properties about its mechanism. However, its downside is complexity of the algorithm because the combination of features grows exponentially. Therefore, in a practical scenario, the Shapley value can only be estimated using a subset of combinations.
SHAP (Shapley Additive exPlanations)
SHAP, which stands for Shapley Additive exPlanations, is an interpretability method based on Shapley values and was introduced by Lundberg and Lee (2017) to explain individual predictions of any machine learning model. When it comes to explaining complex models such as ensemble methods or deep networks, usually simpler local explanation models that are an interpretable approximation of the original model are used. In SHAP, this explanation model is represented by a linear model — an additive feature attribution method — or just the summation of present features in the coalition game. SHAP also offers alternatives to estimating Shapley Values.
One of the estimation approaches is KernelSHAP, in which the concepts of local interpretable model-agnostic explanations (LIME) and Shapley values are combined. KernelSHAP estimates the Shapley value using a weighted linear model where the weights are proportional to those used in Shapley value estimation.
Another alternative is TreeSHAP, which is a model-specific estimation of Shapley values for tree-based machine learning models. Unlike the previously discussed methods, TreeSHAP uses the concept of conditional expectation to estimate feature contribution, as opposed to marginal expectation. The advantage of TreeSHAP is its complexity, which depends on the depth of tree instead of the number of possible combinations of features.
SHAP also provides global interpretation using aggregation of Shapley values. Feature importance can be calculated by computing Shapley values for all the data points and summing the absolute values across all data. Visualization of SHAP together with feature values provides dependence plots, which are helpful in revealing relationships between features and model prediction.
Why are Shapley Values Important?
Model explainability allows us to examine the decision making of a model both at a global and local level. On a global level, we can understand which features contribute to the model outcome and the extent to which they influence the decision of the model. On a local level (each individual data point), we can probe into why the model made a certain decision and provide reasons if needed. Local explainability also allows us to probe into a model’s shortcomings in generalizing over data and the reasons it fails to do so.
How C3 AI Helps Organizations with Shapley Values (SHAP)
The C3 AI Platform leverages SHAP (Shapley Additive exPlanations) in its interpretability frameworks integrated in ML Studio. SHAP can be configured on ML Pipelines, the C3 AI low-code, lightweight interface for configuring multi-step machine learning models. It is used by data scientists during the development stage to ensure models are fair, unbiased, and robust, and by C3 AI’s customers during the production stage to spell out additional insights and facilitate user adoption. In highly regulated industries such as consumer finance, SHAP values have allowed for more complex or “black box” models to be used for making approve/decline decisions by providing the means to generate reason codes for individual decisions as required by law.



