

What is Enterprise AI?
“Do It Yourself” AI?
Software innovation cycles follow a typical pattern. Early in the cycle, companies often take a “do it yourself” approach and try building the new technology themselves. In the 1980s, for example, when Oracle first introduced relational database management system (RDBMS) software to the market, interest was high. RDBMS technology offered dramatic cost economies and productivity gains in application development and maintenance. It proved an enabling technology for the next generation of enterprise applications that followed, including material requirements planning (MRP), enterprise resource planning (ERP), customer relationship management (CRM), manufacturing automation, and others.
The early competitors of Oracle in the RDBMS market included IBM (DB2), Relational Technology (Ingres), and Sperry (Mapper). But the primary competitor to Oracle was not any of these companies. It was in many cases the CIO, who attempted to build the organization’s own RDBMS with IT personnel, offshore personnel, or the help of a systems integrator. None of those efforts succeeded. Eventually, the CIO was replaced and the organization installed a commercial RDBMS.
When enterprise applications including ERP and CRM were introduced to the market in the 1990s, the primary competitors included Oracle, SAP, and Siebel Systems. But in the early years of that innovation cycle, many CIOs attempted to develop these complex enterprise applications internally. Hundreds of person-years and hundreds of millions of dollars were spent on those projects. A few years later, a new CIO would install a working commercial system.
Some of the most technologically astute companies – including Hewlett-Packard, IBM, Microsoft, and Compaq – repeatedly failed at internally developed CRM projects. All ultimately became successful Siebel Systems CRM customers.
Just as happened with the introduction of RDBMS, ERP, and CRM software in prior innovation cycles, the initial reaction of many IT organizations is to try to internally develop a general-purpose AI and IoT platform, using open source software with a combination of microservices from cloud providers like AWS and Google. The process starts by taking some subset of the myriad of proprietary and open source solutions and organizing them into the reference platform architecture depicted in Figure 3.
Figure 3
The AI Software Stack
The “build it yourself” approach requires stitching together dozens of disparate open source components from different developers with different APIs, different code bases, and different levels of maturity and support.
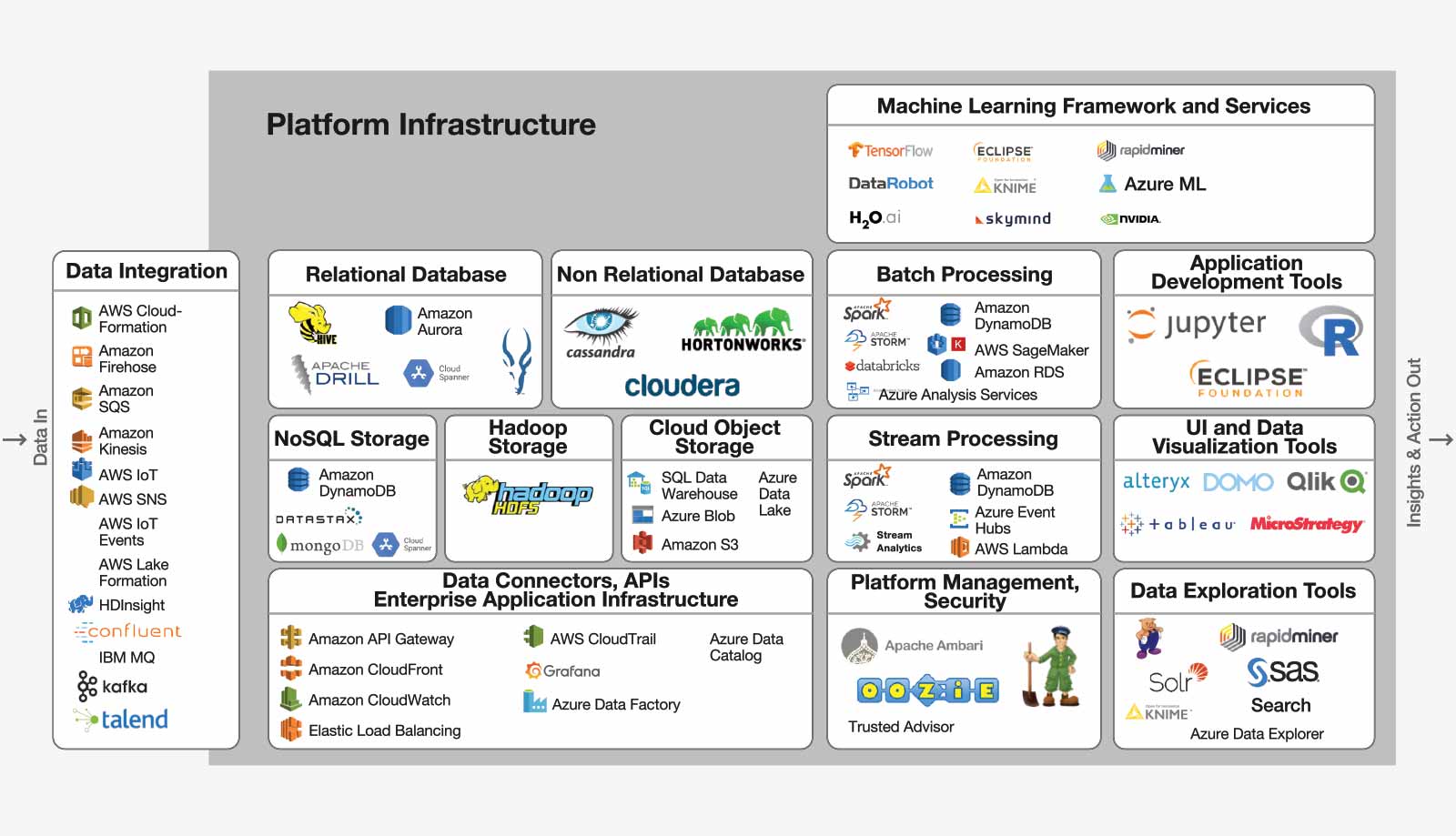
The next step is to assemble hundreds or even thousands of programmers, frequently distributed around the world, using structured programming and application programming interfaces (APIs) to attempt to stitch these various programs, data sources, sensors, machine learning models, development tools, and user interface paradigms together into a unified, functional, seamless whole that will enable the organization to excel at designing, developing, provisioning, and deploying numerous enterprise scale AI and IoT applications.
The complexity of such a system is two orders of magnitude greater than developing a CRM or ERP system. Many have attempted to build such a system, and none have succeeded. The classic case study is GE Digital that expended eight years, 3,000 programmers, and $7 billion trying to succeed at this task. The end result of that effort included the collapse of that division and the termination of the CEO, and it contributed to the dissolution of one of the world’s iconic companies.
Were someone to succeed at such an effort, the resultant software stack would look something like Figure 4.
Figure 4
AI Software Cluster
The “build it yourself” approach requires numerous integrations of underlying components that were not designed to work together, resulting in a degree of complexity that overwhelms even the best development teams.
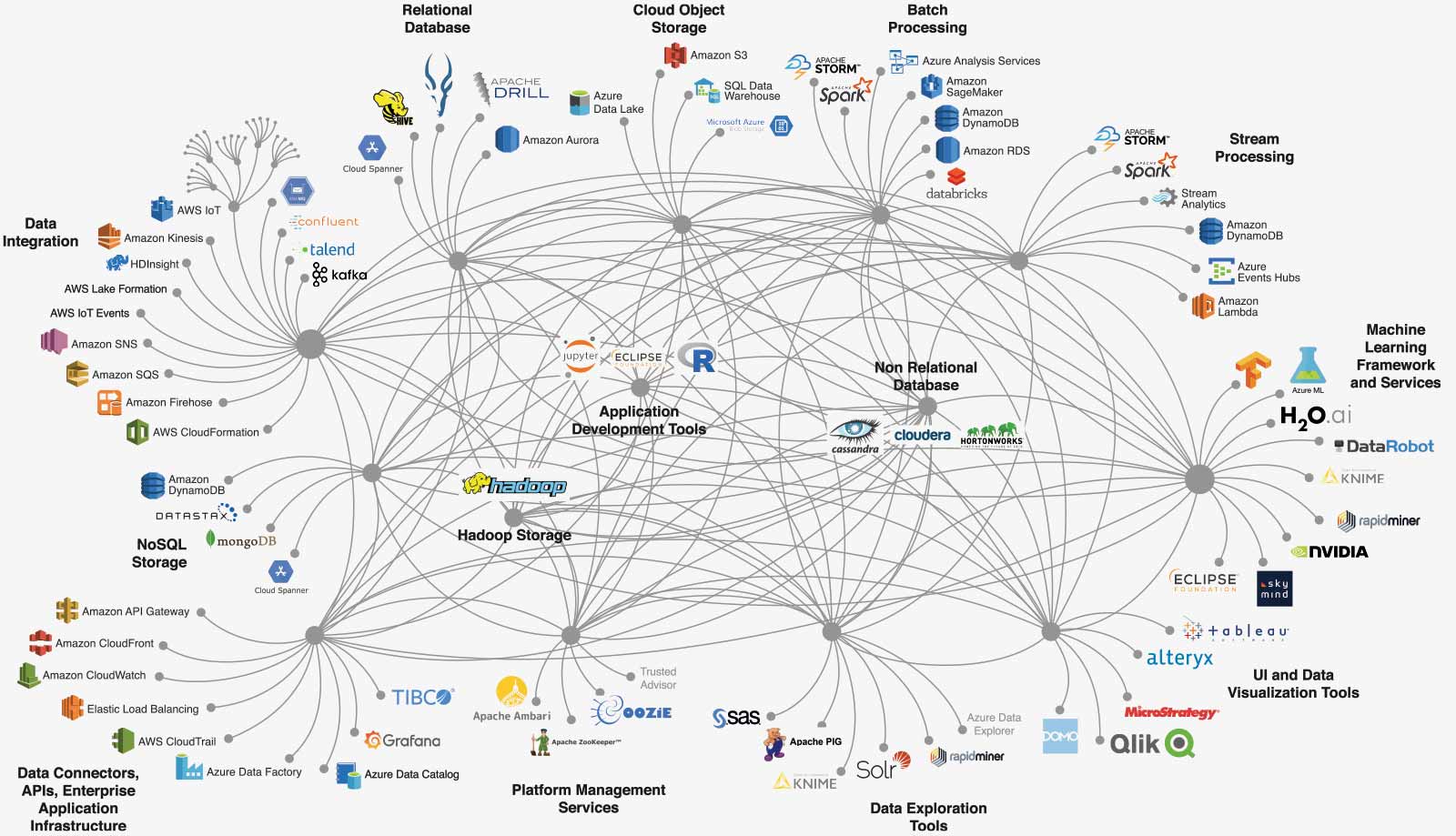
There are a number of problems with this approach:
1. Complexity
Using structured programming, the number of software API connections that one needs to establish, harden, test, and verify for a complex system can approach the order of 1013. The developers of the system need to individually and collectively grasp that level of complexity to get it to work. The number of programmers capable of dealing with that level of complexity is quite small.
Aside from the platform developers, the application developers and data scientists also need to understand the complexity of the architecture and all the underlying data and process dependencies in order to develop any application. The level of complexity inherent in these efforts is sufficiently great to assure project failure.
2. Brittleness
Spaghetti-code applications of this nature are highly dependent upon each and every component working properly. If one developer introduces a bug into any one of the open source components, all applications developed with that platform may cease to function.
3. Future Proof
As new libraries, faster databases, and new machine learning techniques become available, those new utilities need to be available within the platform. Consequently, every application that was built on the platform will likely need to be reprogrammed in order to function correctly. This may take months to years.
4. Data Integration
An integrated, federated common object data model is absolutely necessary for this application domain. Using this type of structured programming API-driven architecture will require hundreds of person-years to develop an integrated data model for any large corporation. This is the primary reason why tens to hundreds of millions of dollars get spent, and several years later, no applications are deployed. The Fortune 500 is littered with such disaster stories.